AI built for operators —
not for demos.
Toretto's AI surfaces aren't bolted-on chat widgets. Every agent runs through a permissioned tool layer, writes through human- confirmed workflows, and leaves a per-step reasoning trail you can audit. Powered by frontier models. The discipline is ours.
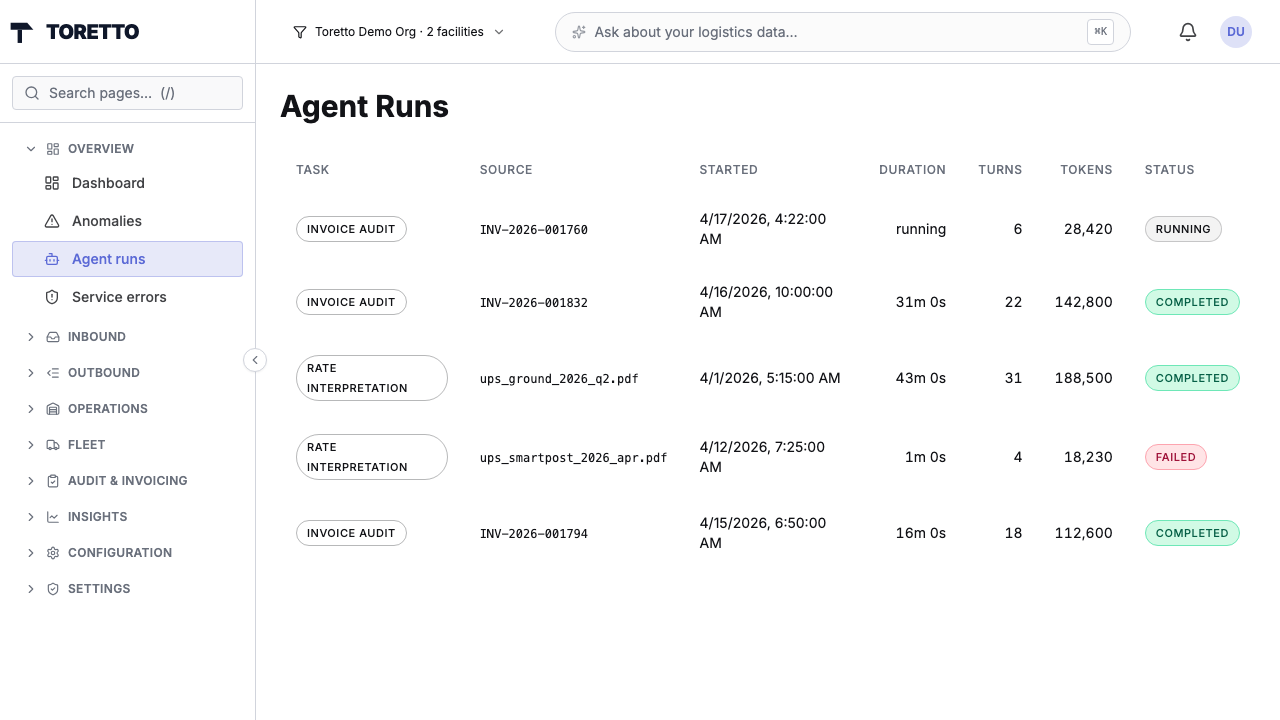
Every agent run is tracked — task type, source, turns, tokens, status. Click into any one to see the reasoning trail.
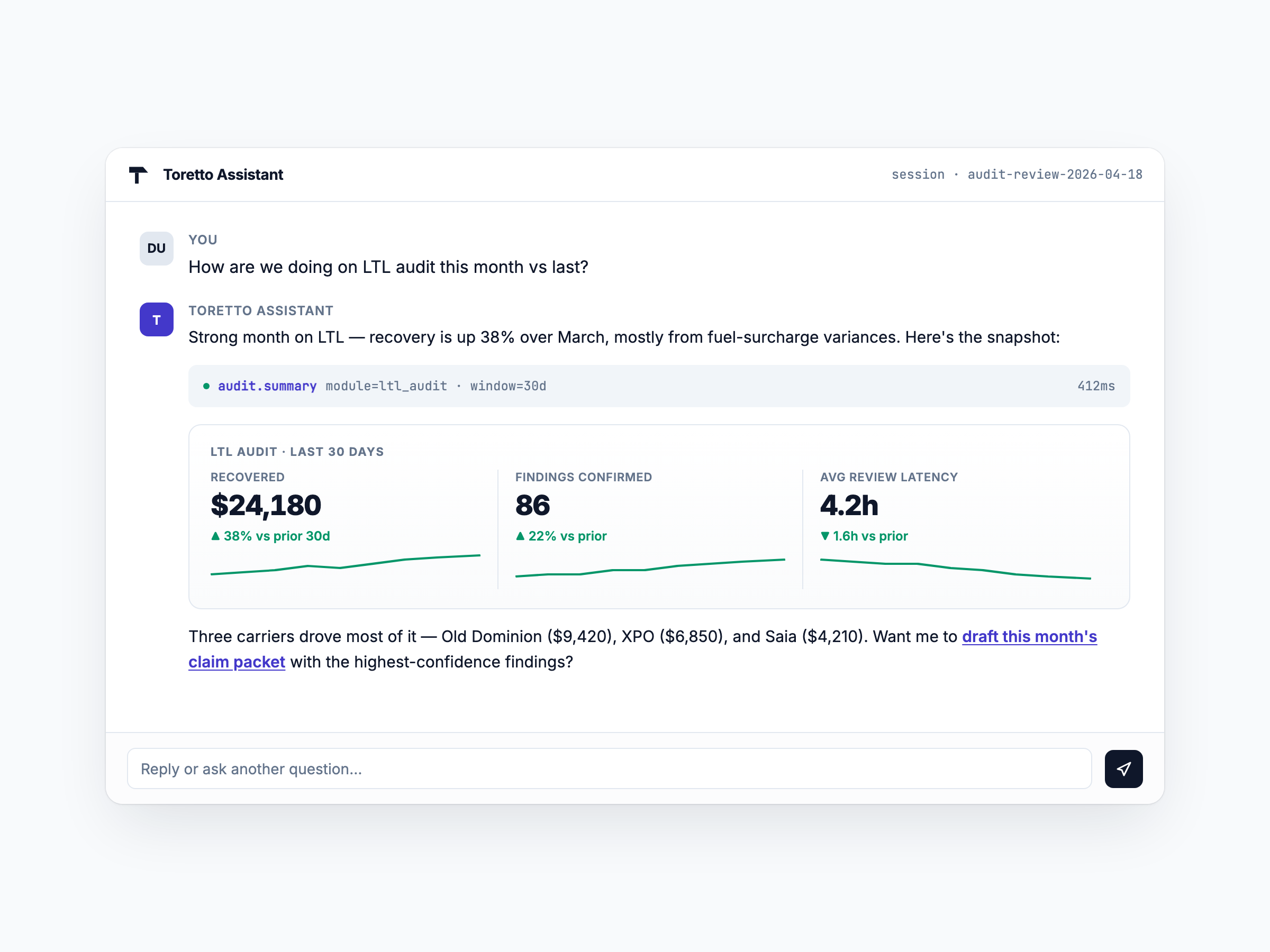
Ask anything about your operation
The assistant pulls live data through the same MCP tools the agents use — KPIs, charts, and follow-up actions surface inline, in the conversation, with the tool call shown for transparency.
What the AI does on the platform
Five concrete capabilities shipping today.
Read any rate card
Upload a UPS, FedEx, DHL, or LTL tariff in PDF or XLSX. The rate-interpretation agent parses it into structured rate tiers — base rates, zones, weight breaks, accessorials, dimensional- weight rules. You review the agent's interpretation before activating, and reparse anytime the carrier sends an update.
- ✓ Multi-page tariff documents
- ✓ Mixed table + prose formats
- ✓ Per-customer override schedules
Audit every line, explain every finding
The audit agent runs a 25–40 turn adaptive-thinking loop against
a tool layer that exposes rate cards, invoices, accessorials,
and service guarantees. Every overcharge or claim-eligible
late delivery comes back with the agent's full reasoning,
stored permanently in agent_run_log for review.
- ✓ Per-finding tool-call trail
- ✓ Append-only audit log (Postgres trigger-enforced)
- ✓ Human confirm-before-claim
Ask, propose, confirm
An embedded chat assistant with read access to your shipments, invoices, rates, and findings — and write access guarded by confirm-before-execute workflows. Ask "tender these 40 LTL shipments at lowest cost" and the assistant proposes a plan, you review it, and the platform executes only on your confirm.
- ✓ Permissioned tool catalog (MCP)
- ✓ Per-tenant data scope, every call
- ✓ Multi-step workflows with pause-for-confirmation
See what changed before you're asked
Continuous monitoring across spend, transit, accessorial mix, and on-time performance. When a carrier silently raises a surcharge or a lane's transit drifts, you see it on the dashboard before the next invoice arrives.
- ✓ Per-carrier, per-lane, per-accessorial baselines
- ✓ Threshold + statistical-drift triggers
- ✓ SignalWatch alerts via Slack, email, webhook
Pick the right carrier for every shipment, every time
The tendering decision engine rates every shipment across every eligible mode and carrier, then applies a policy you control — cheapest, fastest, cheapest within transit, prefer mode, or prefer carrier. Constraints layer on top: lane blacklists, daily capacity caps, accessorial compatibility, service-level floors. Every decision writes an audit trail with both the engine's pick and any operator override — so when a finance review asks "why FedEx and not YRC", the answer is one query away.
tender_shipments tool with dry-runHow the AI is wired in
The assistant explains its own architecture better than we can — here's how a question turns into a finding.
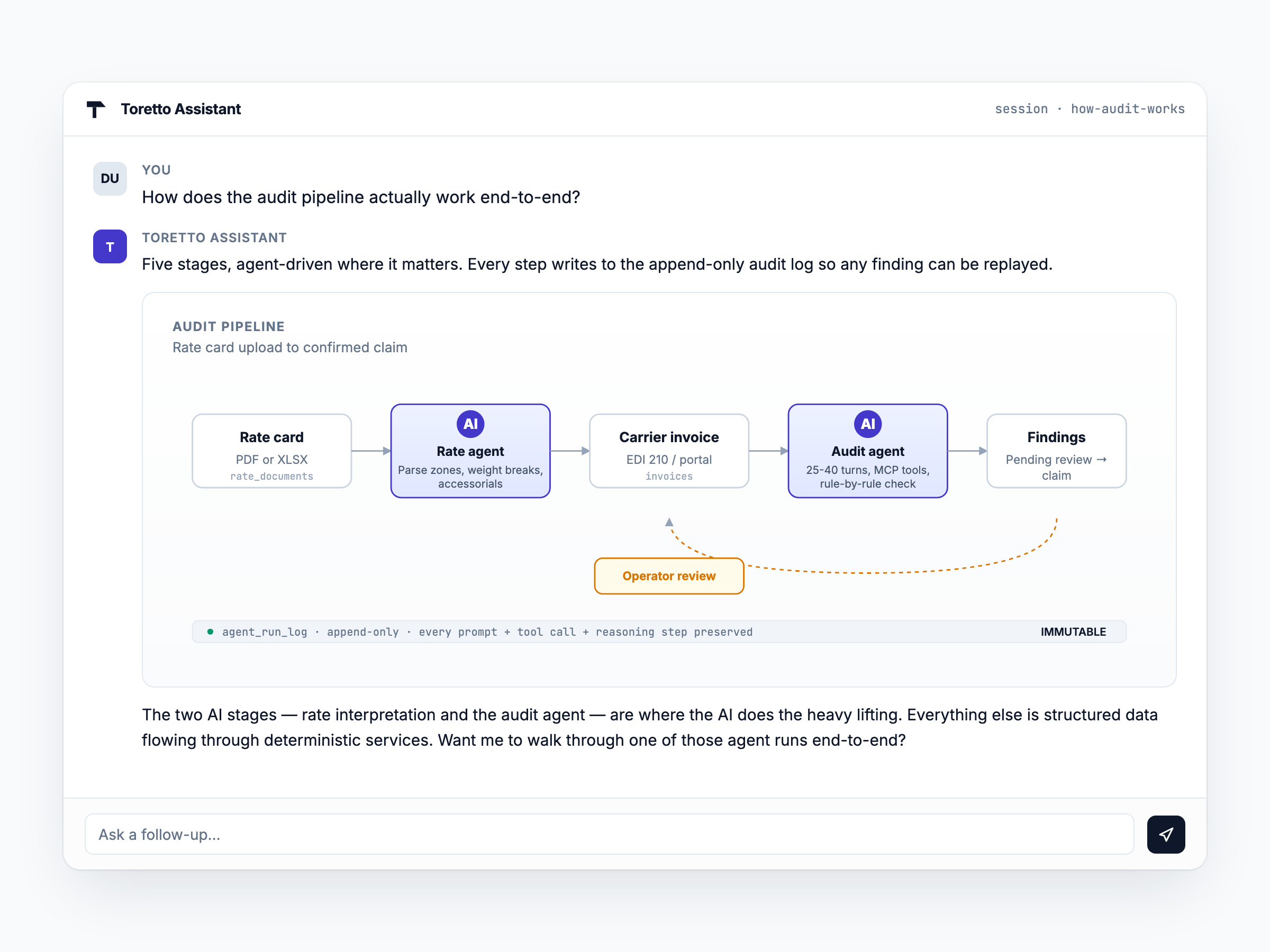
Three principles keep the agents useful and the operator in control.
Agents never touch the database directly
Every read and write goes through a Model Context Protocol (MCP) tool. The MCP server enforces tenant scope, validates inputs, and writes through the same service layer the operator UI uses. The model can't bypass row-level isolation or permissions — even if it wanted to.
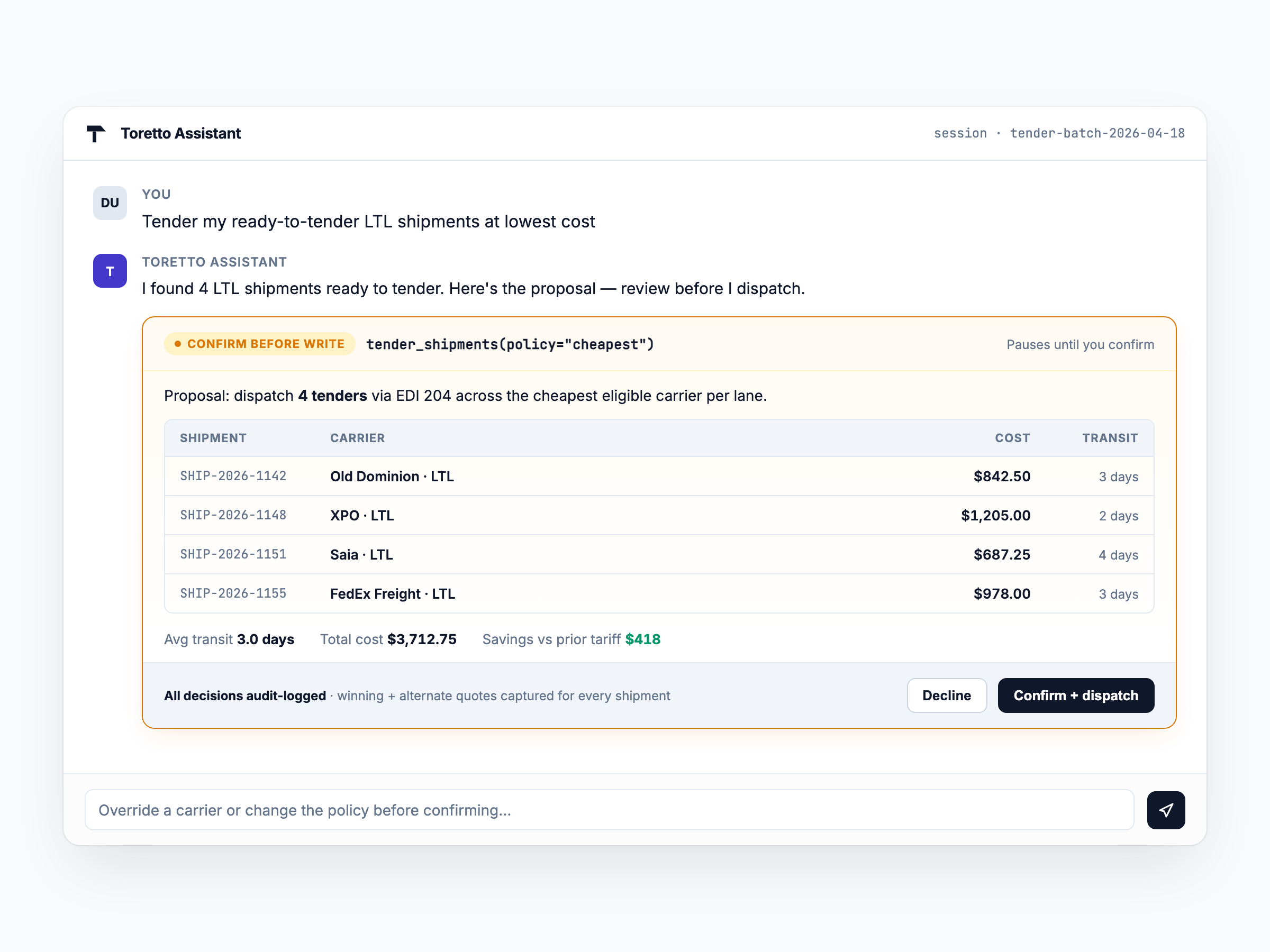
Writes pause for confirmation
Multi-step workflows — batch tendering, claim filing,
rate-card reparses — pause on a
pause_for_confirmation()
primitive. The agent renders a proposal; the operator
confirms, edits, or cancels. Nothing irreversible
happens autonomously.
Every step is auditable, forever
The agent_run_log
table is append-only (Postgres trigger enforced). Every
tool call, every reasoning step, every input and output is
stored. When an audit finding is challenged six months
later, you replay the exact chain that produced it.
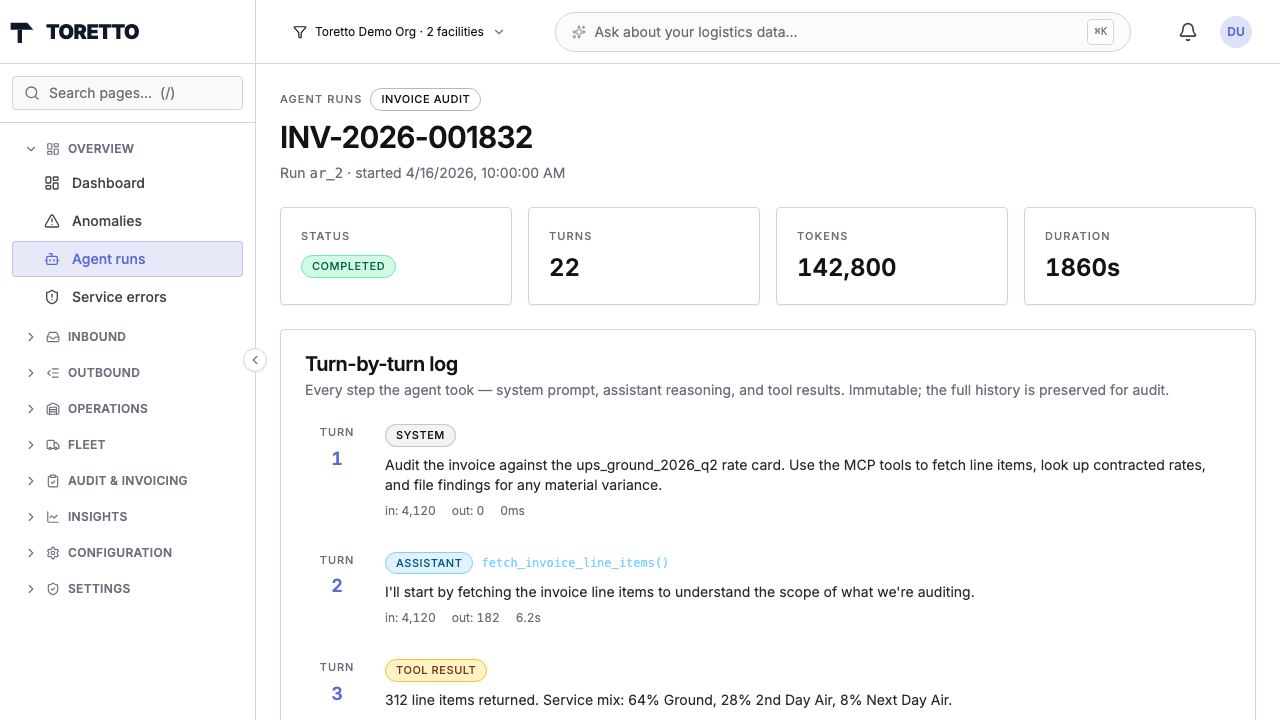
A real audit agent run — every turn labeled, every tool call captured, every token counted.
Built on frontier models
Toretto runs on best-in-class frontier models — chosen for tool-use reliability, document parsing strength, and adaptive thinking on long agentic loops. We don't lock you to a model: the agent layer abstracts the provider so we can move on price/performance shifts.
Prompt caching is enabled by default on every long-context tool invocation. Token spend per audit is tracked, attributed, and metered at the org level.
Stays yours
Your invoices, rate cards, shipment data, and findings are stored in your tenant — never used to train models. API calls to our model provider run under enterprise no-training-on-API- data terms, and we never share your data across tenants.
On the audit side, all credentials (carrier portal logins, EDI VAN keys, telematics tokens) are stored with AES-256-GCM envelope encryption — never in plaintext, never exposed to the agent layer.
See an AI audit run on your own data
Bring a rate card and an invoice. We'll run the audit agent live in front of you — and you'll see every reasoning step, every tool call, and every finding the model surfaced.